 微信关注,获取更多
微信关注,获取更多 作者 | 陈泊丞
在今年,于整个AI圈里,最为热闹的事件是全民“养龙虾”,有着OpenClaw的走红,使得大家最终看到了AGI 落地的具象化可能。
可是,在业界因Agent“手脚”愈发灵活而庆祝这件事情的时候,一个更为根本的问题却被暂且遮盖住了,那就是真正对OpenClaw行动价值起到决定作用的“大脑”,也就是它背后的大模型底座,好像正处于一条无法持续下去的道路上。
在过去的两年当中,大模型这个行业所奉行的是那种典型的“暴力美学”,也就是说参数越多意味着其所代表的智能程度就越高,思维链只要越长那么就代表着推理也就越深。万亿参数的模型是接连不断地登场亮相,长思维链一度成为了技术先进性的标配存在。然而在这股狂热的氛围之下,一个尴尬的事实却是逐渐地浮现而出,那就是大量的参数仅仅只是那种“吃算力”的摆设而已,超过70%的Token消耗是发生在模型“已然答对、却仍在反思”的这个无效阶段。
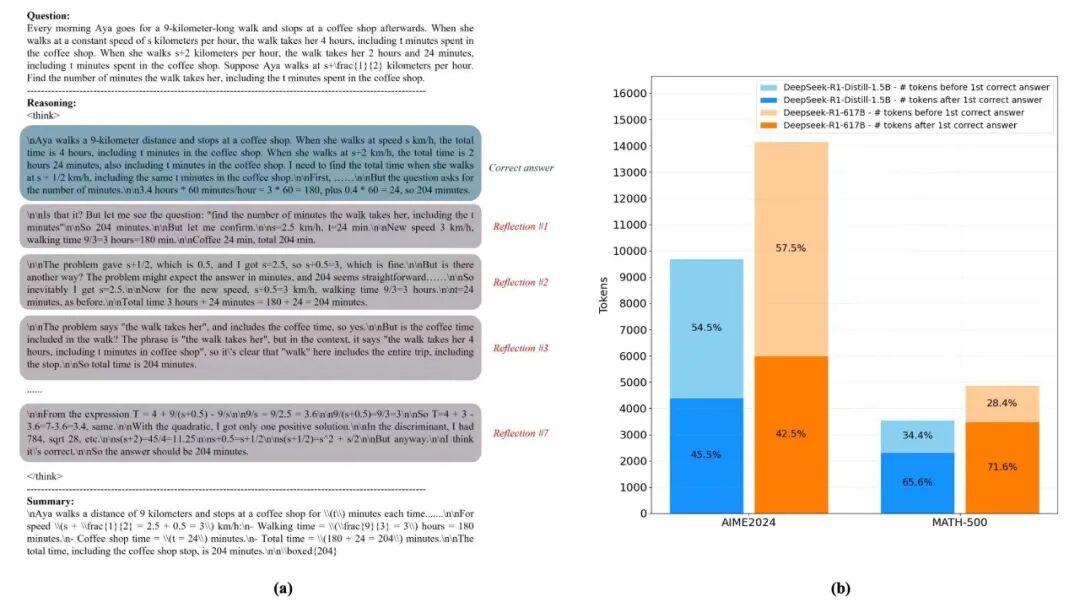
推理Token消耗分布示意
所以,当像OpenClaw的这种执行端已然准备妥当要进入工厂,要进入仓库,要进入办公室时,我们才发觉,驱动它的那个“大脑”,要不然就是贵到企业根本用不起,要不然就是为了节省成本而不得不“降智”。这说不定就是2026年AI产业化最关键的悖论,——执行端的手脚已然就位,然而大脑还在“算力通胀”的困境里苦苦挣扎。
这一处于困境的局面该通过怎样的方式来打破呢?就在距离现在时间不算长之前,YuanLab.ai团队将Yuan 3.0 Ultra万亿参数模型进行了开源,采用了完全不同于其他的、更为注重实际的技术路线方向,也在尝试着去解答当下这个行业所面临的这一具有根本性特征的问题,那就是当模型规模的扩大已经触碰到收益逐渐减少的那个临界要点的时候,大模型接下来的一场如同竞赛般的发展进程,究竟应该比拼的是什么呢?
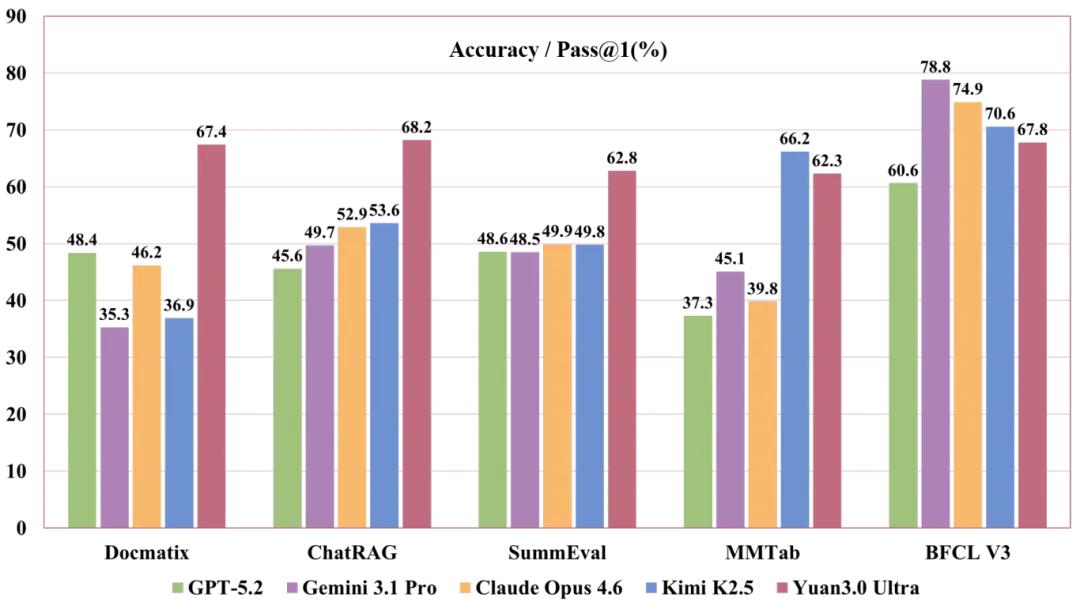
Yuan3.0 Ultra在面向企业应用的表现
要是OpenClaw的脑子,被困在了“价格不菲”跟“才智降低”这样的两难境地之中,那么,整个行业就得再次去审视那个往昔一直被当作准则的增长逻辑了。
算力通胀时代,市场渴望一场“价值回归”
过去两年,行业经历了一场深刻的认知撕裂。
与技术供给侧的狂欢相对的是被撕裂的另一边,万亿参数模型接连不断地登场亮相,推理模型持续追逐越来越长的思维链,似乎“思及越多”便等同于“思及越准”,在国际AI顶会上,论文举足轻重、备受关注的核心卖点常常是“我们所拥有的模型又增大了多少亿”“我们打造的思维链距离原始链条步数上又叠加变长了若干”,此类状况甚嚣尘上、泛滥不止。
技术营销喧嚣退去之时,企业需求侧在清醒地面对撕裂的另一边,企业客户于采购之际,以最朴素且最残酷的ROI逻辑进行发问,每一次API调用所支付的Token费用,究竟有多少数值转化为了真正的业务价值呢?
实际上,经过研究显示,于复杂推理任务里,模型超过百分之七十的Token消耗是发生在“已然答对”之后的自我验证阶段。这表明,企业每给模型智能支付十元钱,其中有七元是在为它的“过度思考”去买单。
与此同时,更隐蔽的浪费隐匿于模型结构自身。MoE(混合专家)架构在预训练期间会自动形成专家分化,负载最高的专家跟最低的专家之间差额能够达到500倍。这表明,大量长期处于闲置状态的“僵尸专家”成为了模型参数虚高的主要促使者——它们几乎不开展工作,不过依旧会在每一次推理之际被加载,被维护,被计费。
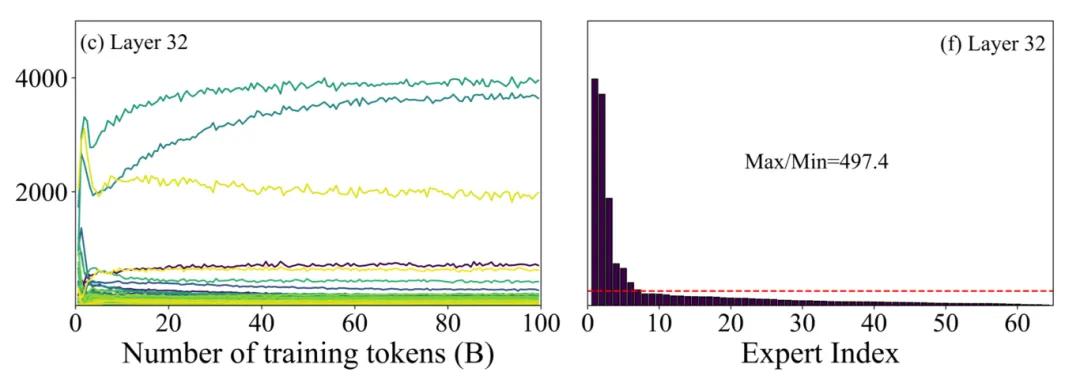
MoE模型训练过程中存在专家训练不均衡问题
因此,“算力通胀”这一问题,就必须得予以重视了。参数规模正处于膨胀状态,推理链条也在不断拉长,然而单位算力所产出的真实智能却正在被稀释。当OpenClaw这类执行端开始进行规模化部署时,这种“通胀”所带来的成本压力便被成倍放大了——每一次物理动作的背后,都是数量众多的Token在被消耗掉了。
今日,YuanLab.ai团队已然敏锐觉察到这一趋势无法持续,于此前发布的Yuan 3.0 Flash内,他们首度验证了“反过度思考”技术可施行性,借由RIRM(Reflection Inhibition Reward Mechanism,反思抑制奖励)机制使模型学会在恰当之际停下。Yuan 3.0 Ultra开源之前,这一理念只是停留在“效率优化”层面,之后在此基础上进一步提升到了“范式定义”的高度,在行业还只一味比拼谁能堆砌出规模更大的模型的时候,实际上真正体现竞争力的较量已经在悄然间朝着另一个方向转移,就是思考谁能够运用更少一些的计算力从而提炼出相对更具成效的智能。
是时候对“万亿参数”祛魅了
就客观的角度来讲,Yuan 3.0 Ultra的具备突破性的地方,并非在于它进入了万亿俱乐部,而是在于它针对“万亿参数”这个概念自身,达成了一次完全的“祛魅”。
其一,存在着对于“参数规模”的祛魅情况,LAEP算法能够使得模型学会“精简”。
有一个在行业里长期存在着的思维定式,即参数越多,模型就越强,这样的一种认知是如此地根深蒂固,以至于每当有厂商发布了更大参数的模型时,资本市场都会给出积极的反馈。
Yuan 3.0 Ultra凭借自适应专家裁剪算法,也就是Layer-Adaptive Expert Pruning,简称LAEP,戳破了这一神话,研究团队发现,MoE模型在预训练的时候会自然形成专家功能分化,然而分化并不等同于优化,大量低贡献的专家长期处于闲置状态,却依旧消耗着宝贵的算力资源。LAEP算法有着精妙之处,在于它宛如一位清醒的“组织优化顾问”,于训练进程里动态识别那些冗余专家,并且予以裁剪,把初始的1515B参数优化成1010B,参数规模减小了33.3%,而预训练算力效率却反而提升了49%。

Yuan3.0 Ultra采用LAEP显著提升预训练效率
以企业的角度来说吧,这所代表的意义在于能够凭借着更低的硬件准入条件 ,以及更少一些的GPU租赁方面的支出费用 ,进而取得和那个1515B参数模型相等同的一种旗舰级别的智能方面的支撑。那么 ,在别人仍旧针对参数规模竞赛在支付费用的时候 ,Yuan 3.0 Ultra的用户已然在尽情享受那种经过“减重”之后的成本层面的红利了。
二、针对“思维链长度”进行祛魅处理,RIRM 机制能够使模型明白“停”的那种智慧。
当整个行业都沉浸于“让模型思考得更为长久”之时,一个具有根本性的问题却被忽视掉了:究竟会在什么时候该停止下来? 这可不单单只是效率方面的问题,更是关乎安全的问题。
去设想一下,有一个由OpenClaw进行驱动的工业机器人,要是它的“大脑”辨认出安全隐患之后,还要不断地反复思索、再三去进行确认,哪怕仅仅只是产生几秒钟的延迟,那都极有可能导致事故的发生。在现实的世界当中,“想得过多”跟“想错”同样存在着危险。
在此情况之下,被Yuan 3.0 Ultra引入的那个反思抑制奖励机制即RIRM,确切而言正是针对那种“长思维链崇拜”所进行的,一次精准不已的纠偏举措。它并非是以简单又粗暴的方式去截断输出,而是借助强化学习训练,使得模型能够学会区分开来两种状态,即什么时候是需要继续展开推理的,以及什么时候已然是可以停止的。那个研究团队把最大能够接受的反思步数设定为3,在理想状态当中鼓励直接做出响应,面对复杂问题的时候允许进行适度的反思,然而一旦超过了那个阈值,奖励机制便会自动启动抑制。
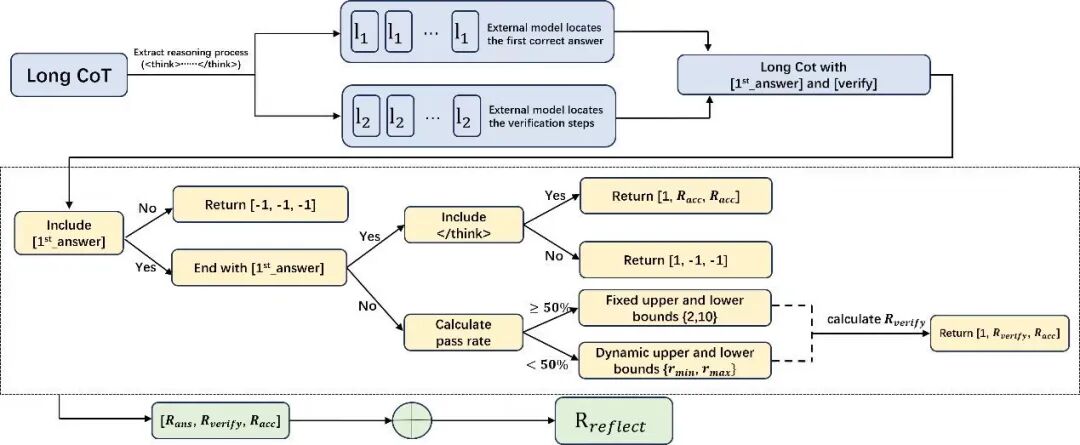
RIRM工作流程示意
并且,训练的准确率提高了百分之十六点三三,与此同时,平均响应的长度减少了百分之十四点三八。于MATH – 500基准那里,反思阶段的Token消耗明显降低 这种“该停就停”的能力,于企业高频调用场景里所产生的价值,远比在单一benchmark上刷出百分之零点一的提升要大得多。当每一回API调用都在为企业节省费用,而非为模型的“内心戏”付费的时候,规模化应用才切实成为了有可能的事情。
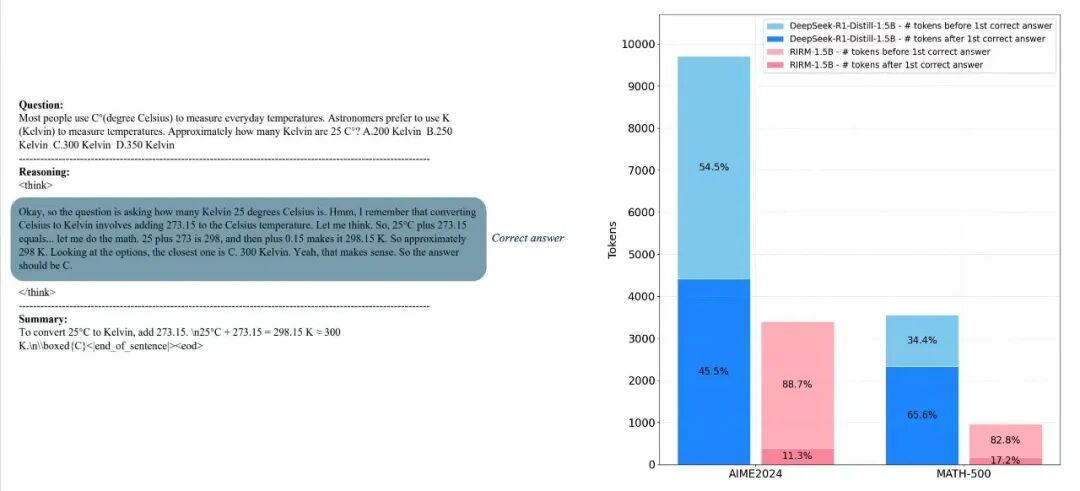
RIRM训练前后Token消耗对比
三、对“多模态”的祛魅:LFA机制让模型专注“有效关联”。
多模态,是AI行业长久以来的又一热门词汇。然而,多模态并非单纯的图文拼接,更不是将图片与文字丢进同一个模型就大功告成。企业于真实业务场景里的多模态,常常是财报中图文混合排列的繁杂表格,是合同里穿插的扫描件以及手写批注,是技术文档内跨页面相互关联的图表和数据。所以,处理这些信息时,所需的并非是具备“什么都能看”这种宽泛能力,而是拥有“能看懂重点”这种精准穿透力。
Yuan 3.0 Ultra所引入的局部过滤注意力机制,也就是Localized Filtering-based Attention,简称LFA,正是出于这个目的而出现的。 此机制依靠强化对核心语义的聚焦, 精确地过滤掉无效注意力干扰, 从而使得模型在处理复杂文档之际, 不会再被噪声信息所误导。如此这般针对于“有效信息”的聚焦本领,令像OpenClaw这类的Agent在开展具体的任务之际,能够切实明白“该查看些什么”“该忽视些什么”,进而达成所谓“眼睛”与“大脑”的协同进化。
总体而言,这三重“祛魅”一起所指向的,恰恰是Yuan 3.0 Ultra的关键主张:有效智能。从企业的角度来看,“有效智能”并非只是一句口号,而是能够被量化的ROI,随后能够以更低的成本投入去获取更优质的AI智能服务。这就表明,企业无需再为“听起来厉害”的参数掏钱,而是为“用得上”的智能支付费用。
大模型竞争的下半场已经开启了
当 “有效智能” 在市场上被聚焦,这就意味着大模型竞争的下半场已然拉开了序幕。那么,在头部厂商纷纷把模型权限收紧,构建起封闭生态的时候,YuanLab.ai团队却以一种开放姿态,贡献出万亿级的核心模型,而其背后的本质,其实就是在参与去定义大模型竞争的下半场。
回到上半场,关键在于“参数竞赛”,即先到达千亿、万亿的一方,便是技术领先者,在榜单上刷出更高分数的人,会得到资本与市场的青睐。
这一段时期的逻辑简便径直,可也很快碰到天花板,就是参数堆积导致的边际收益递减,然而边际成本像算力设备耗电、计算所用能量、展开布置的困难程度却呈现指数级攀升。从2025年末开始,数目逐渐增多的从业者察觉到,只是单纯地相较参数大小,已然没法维持下去了。
展望下半场,首先核心在于“效率竞赛”,具体是谁能够运用较低的算力达成相同的智能,是谁能够凭借更可控的成本来支撑复杂的 Agent 任务,才堪称真正的产业赋能者。这场竞赛不存在简单的量化指标,而是要测试对模型架构具备深入全面的见解、需考量对算法效率开展系统优化、还要检验对企业场景实现精准适配。
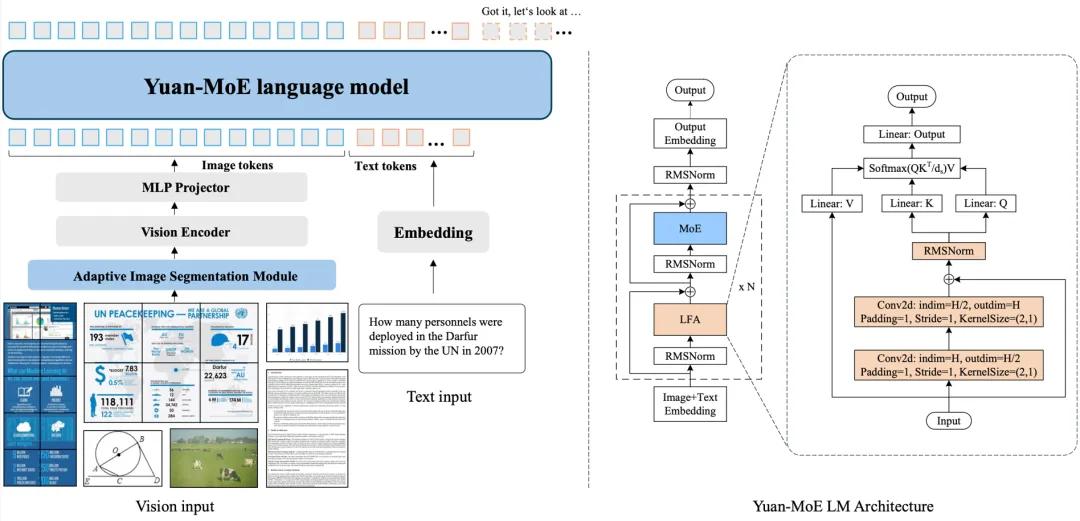
Yuan 3.0整体架构和基于MoE的语言主干
到了下半场的时候,智能所含的纯度,相较于参数的数量而言,是更加重要的;思考所具备的效率,跟思考的长度相比较,是更具价值的。如此一来,Yuan 3.0 Ultra凭借LAEP、RIRM、LFA等方面的创新,从系统层面解答了“智能的效率”这个关键命题,给行业确立了有效智能的全新标杆。
从更深入的层面去观察,Yuan 3.0 Ultra进行开源所具有的战略价值还体现于,它为中小企业、用于科学原理及应用等方面探索的专业机构以及从事不同行业开发工作的人们,提供了一种称得上旗舰水准、能够按照自身需求加以定制、不会受限被锁定的模型底部支撑的选择。当下这个时候,从事开发工作的人员们已经能够在github网站有关项目的开源网址https://github.com/Yuan-lab-LLM/Yuan3.0那里获得与之对应的能力。
就算OpenClaw这类Agent框架不断成熟迈向发展起来的时候,企业最急切需要的偏偏是一个可以在深度方面与自身业务相适配,并且成本在可控范围之内的“大脑”。Yuan 3.0 Ultra的开源,从本质上来说是在为下一波Agent应用数量突增进行基础设施的铺设——让所有意图“养龙虾”的企业乃至是个人,都能够承担得起一个心智聪慧的大脑。
结语
在2026年的时候,当“养龙虾”变成全民都在谈论的话题,当Agent开始真实地进入到各行各业,我们比以往任何时候都更加需要去回答那个最为根本的问题,那就是什么样的智能,才是值得企业为之付费的智能呢?
答案是,具备效力的智能。当行业最终察觉到,真正的智能,并非是那种毫无节制地消耗算力的本事,而是善于运用算力的聪慧——于此之际,大模型的下半场就算已然正式开启了。全新的增长逻辑,正在被再度界定,并主导着下半场的竞争。
未经允许不得转载:openwrt技术分享 » OpenClaw开源项目手脚已备,大脑算力困局咋破?

