 微信关注,获取更多
微信关注,获取更多 对于身为开发人员的这个人而言,有可能听说过FPGA,甚至在那种存在于大学期间的课程设计里面,有可能借助FPGA去开展过跟计算机体系架构相关的验证工作,然而对于FPGA形成的第一印象,有可能觉得这乃是硬件工程师所从事的事情呀。
当下,伴随人工智能的兴起,GPU 通过深度学习,步入了历史的舞台,而且正热火朝天地运行着各类业务,从训练到推理它都存在,这浪潮之中,FPGA 也缓缓朝着数据中心走去,施展着它的长处 ,起着它的优势。接下来于是就说说,FPGA怎样能够使程序员们更友好地开展开发,而无需去写烦人那般的RTL代码,不必运用VCS、Modelsim这类仿真软件,便能够轻松容易实现_unit_test。
因 FPGA 通过 OpenCL 得以实现编程,使得程序员仅经由 C/C++ 添加恰当的 pragma,这就达成了这一编程思想的转变。为使您经由 OpenCL 实现的 FPGA 应用具备更高性能。您需熟知如下所介绍的硬件。另外,还会介绍编译优化选项。其有助于将您的 OpenCL 应用更妥善地实现 RTL 的转换与映射。并部署至 FPGA 上予以执行。
FPGA 概览
FPGA乃高规格集成电路,其可经由持续配置与拼接,达成具无限精度的函数功能,缘由在于它和CPU、抑或GPU有所不同,其基本数据类型的位宽是固定的那种情况并非和它一样嘿,反而FPGA在这方面能够做得极为灵活。于使用FPGA之际,它格外适配某些low – level操作,就像bit masking、shifting、addition此类操作均可极易实现,这点很特别。
为了达成并行化计算,FPGA内部存有查找表(LUTs),有寄存器(register),具备片上存储(on-chip memory)以及算术运算硬核(像是数字信号处理器 (DSP) 块),这些FPGA内部的模块借由网络连接到一起,经由编程的方式,能够对连接予以配置,进而达成特定的逻辑功能,这种网络连接可重配的特性给FPGA赋予了高层次可编程的能力。FPGA的可编程性,体现在那改变的方面,是各个模块之间,以及逻辑资源之间,二者的连接方式。标点符号。
比如说,查找表也就是 LUTs 所展现出的 FPGA 可编程能力,对于程序猿而言,能够等效理解成一个存储器,也即是 RAM。针对 3 – bits 输入的 LUT,能够等效理解为一个具备 3 位地址线还有 8 个 1 – bit 存储单元的存储器,也就是一个长度为 8 的数组,该数组内每个元素是 1bit。那么,当有实现3 – bits数字按位与操作这种需求情况下,存储在8长度数组里面的,是3 – bits输入数字按位与之后的结果,这种结果,一共有8种可能性。当面临实现3 – bits按位异或的状况之时,8长度数组所存储的,却是3 – bits输入数字按位异或得出的结果,这结果同样一共是8种可能性。如此这般,在一个时钟周期这样的时间段内,3 – bits的按位运算就能够被获取到,而且,实现不同功能的按位运算,它是完全具备可编程特性的(这就等同于修改RAM内部的数值呢)。
输入为3-bits的LUT,实现按位进行与操作,也就是bit-wiseAND:
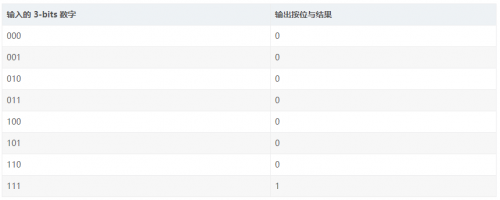
注:3-bits 输入 LUT 查找表
我们所看到着的,是三输入的按位与操作,呈现如下情形,于 FPGA 内部,能够借助 LUT 予以实现。
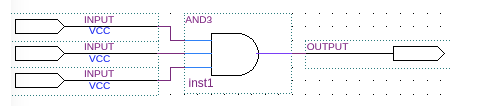
像上面所呈现出来的那样,展示了有着 3 输入,以及 1 输出的 LUT 实现情况。当把 LUT 通过并联,并且还有串联等方式结合到一起之后,就能够实现更为复杂的逻辑运算了。
传统 FPGA 开发
▍传统 FPGA 与软件开发对比
说起传统的 FPGA 开发,还有软件开发,工具链,能够借助下表,来进行简单的对比,没错。
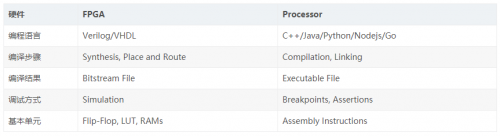
注:传统 FPGA 与软件开发对比表
着重介绍一下,编译阶段的Synthesis(综合),这部分跟软件开发的编译存在较大区别。一般的处理器,像CPU、GPU等,都是业已生产出来的ASIC,有着各自可用的指令集。然而对于FPGA,全部皆为空白,有的仅仅是零部件,一无所有,不过能够自行创造任何结构形式的电路,自由度相当高。这种自由度既是FPGA的优势,亦是开发过程当中的劣势。
写到这里,让我想起了最近 《神秘的程序员们》中的一个梗:



注:漫画来源《神秘的程序员们 56》by 西乔
以往的 FPGA 开发恰似 10 岁之际的 Linux,若想吃一块蛋糕,就得亲自自原材料起始去加工。FPGA 就是这般情形,要是想达成一种算法,就得撰写 RTL,就得设计状态机,还得仿真其正确性。
▍传统 FPGA 开发方式
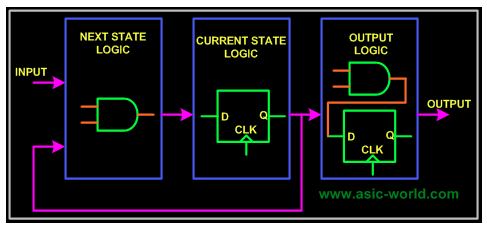
倘若要应对复杂系统,只要需运用有限状态机(FSM),通常而言就得去设计如下包含的三部分逻辑,分别是组合电路,以及时序电路,还有输出逻辑。凭借组合逻辑来获取下一个状态到底是什么,而时序逻辑是用来存储当前状态的,输出逻辑则是混合了组合、时序电路,进而得到最终输出结果。
然后,针对具体算法,设计逻辑在状态机中的流转过程:
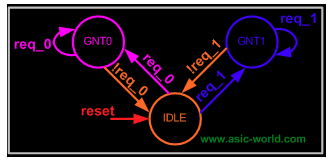
实现的 RTL 是这样的:
模组,有限状态机,使用,单一的,总是块句式,(。
); // =============输入端口============================ ;有输入时钟 ,有复位信号 ,有请求 0 ,有请求 1 ; // =============输出端口=========================== ;有输出授权 0 ,有输出授权 1 ;// =============输入端口数据类型=================== ;有连线时钟 ,有连线复位信号 ,有连线请求 0 ,有连线请求 1。// =============输出端口数据类型================== ;有寄存器授权 0 ,有寄存器授权 1。// =============内部常量====================== ;有参数大小为 3。
参数IDLE赋值为3位二进制数001,GNT0值为3位二进制数010,GNT1值是3位二进制数100 , //**************内部变量开始罗列*********************//一个基于大小尺码规则【从序号大小减1至0大小排列】的寄存器状态变量state //有限状态机中的顺序部分状态变量reg //基于大小尺码规则【具体从序号大小减1至0大小排列呀】一个寄存器下一个状态变量next_state //有限状态机中的组合逻辑部分变量reg,//**************代码从此处正式起始************************************************************始终基于时钟信号上升沿触发执行操作【此处定义一个代码段落标记名为“FSM”】开始执行代码片段 //如果复位信号reset值等于1位二进制数’1′ 则开始执行操作。
state 《= #1 IDLE;
gnt_0 《= 0;
gnt_1 《= 0;end else
case(state)
IDLE,要是req_0等于1‘b1,那就开始。
state 《= #1 GNT0;
gnt_0小于等于1;结束,否则如果(req_1等于1位二进制的1)开始。
gnt_1 《= 1;
状态小于等于 #1获取下一令牌;结束,否则开始。
state 《= #1 IDLE; end
如果,请求零等于一位二进制的一,那么就开始 ,就开始相关操作 ,就开始执行后续步骤。
声明小于等于,编号为1的通用网络定时器;结束,否则开始。
gnt_0 《= 0;
state 《= #1 IDLE; end
GNT1:要是(请求一等于单比特一),那么就开始。
state 《= #1 GNT1; end else begin
gnt_1 《= 0;
state 《= #1 IDLE; end
default : state 《= #1 IDLE;
终止情况结束,结束,模块完毕 ,这标记着仲裁器模块的结束。
针对于程序员而言,传统的RTL设计简直如噩梦般萦绕,那是梦,是令人惧怕的梦啊,啊~~~其工具链全然不同,开发思路也截然不同,还必须要去分析时序,一旦一个Clock节拍未臻准确,便得推倒原样重新来过,务必重新进行验证,所有的一切都显得极为底层,着实不太便利。既然如此,那就将这些交付给专业的FPGAer吧,接下来所介绍的运用OpenCL开发FPGA,仿佛有点类似25岁时的Linux了。因有了高层次的抽象,所以在使用时自然而然会愈发便利。
▍基于 OpenCL 的 FPGA 开发
OpenCL为FPGA开发注入了全新活力,它是一种面向异构系统的编程语言,把FPGA当作异构实现的可选设备之一。整个程序的执行流程由CPU Host端把控,FPGA Device端作为异构加速的一种途径存在着。异构架构有利于解放CPU,把CPU不擅长的处理方式,下放到Device端去处理。当前典型的异构Device包含:GPU、Intel Phi、FPGA。
异构平台编程框架 OpenCL,其主要异构设备含 CPU、GPU、DSP、FPGA 以及其他一些硬件加速器。OpenCL是依据C99来开发设备端代码 ,且提供了相应可调用的API。OpenCL能够输出标准并行计算接口 ,以此来支持任务并行和数据并行这类计算方式。
OpenCL 案例分析
此地运用,Altera官网之处,矩阵乘法之案例,来予以分析。能够借由如此链接,去下载案例:Altera OpenCL Matrix Multiplication。
代码结构如下:
这是一个文件目录结构,其中有一个名为common的文件夹,在common文件夹内,又有一个名为inc的文件夹,在inc文件夹里,有一种名为AOCLUtils的文件类型集合,这些文件包括名叫aocl_utils.h的文件,还有叫opencl.h的文件,以及称为options.h的文件,另外还有名为scoped_ptrs.h的文件,在common文件夹中,还有一个叫readme.css的文件,在common下还有一个名为src的文件夹,src文件夹里,还有同样名为AOCLUtils的文件类型集合,这些文件里包含名为opencl.cpp的文件,还有名为options.cpp的文件,而这整个大结构里还有一个名为matrix_mult的部分,最终构成了这样一个特定的分层文件及部分结构体系。
|– Makefile
|– README.html
|– device
| `– matrix_mult.cl
`– host
|– inc
| `– matrixMult.h
`– src
`– main.cpp
在其中啊,与 FPGA 相关联的代码乃是 matrix_mult.cl ,这一部分的代码是对 kernel 函数进行描述的,而这部分函数呢,会借助编译器去生成 RTL 代码,随后将其 map 到 FPGA 电路当中。
kernel 函数的定义如下:
__kernel
你提供的内容看起来像是代码中的某种特殊语法或指令,不太明确具体要如何按照要求改写。请你明确一下改写的具体方向或示例改写后的样子等更多信息,以便我更准确地完成任务。
由__attribute((num_simd_work_items(SIMD_WORK_ITEMS)))修饰的,名为void matrixMult的函数,其参数之一是__global float *restrict C。
__global float *A,
__global float *B,
int A_width,
int B_width)
模式相对固定,要留意的是,__global 表明从 CPU 传来的数据,放置到全局内存地带,这可以是 FPGA 片上用以储存的资源,DDR,QDR 等等,这会依据 FPGA 的 OpenCL BSP 驱动存在差异。num_simd_work_items 用来标明 SIMD 的宽度。reqd_work_group_size 标明了工作组的规模。这些概念,能够参照 OpenCL 的使用手册。
函数实现如下:
// 对本地存储进行声明,将数组中的某一分块暂时存放,局部浮点数类型二维数组A_local设为包含具体尺寸的数组形式,尺寸为BLOCK_SIZE行和BLOCK_SIZE列。
__本地浮点型数组B_local[BLOCK_SIZE][BLOCK_SIZE];,这是块索引,整型变量block_x等于获取组ID(传入参数为0),整型变量block_y等于获取组ID(传入参数为1),这是本地ID索引,也就是在一个块内的偏移量,整型变量local_x等于获取本地ID(传入参数为0),整型变量local_y等于获取本地ID(传入参数为1),计算循环边界,整型变量a_start等于A宽度乘以BLOCK_SIZE再乘以block_y,整型变量a_end等于a_start加上A宽度再减1,整型变量b_start等于BLOCK_SIZE乘以block_x,浮点型变量running_sum初始化为0.0f,对于从a_start、b_start开始,当a小于等于a_end时,a每次增加BLOCK_SIZE,b每次增加(BLOCK_SIZE乘以B宽度)的循环来说。
通过,从全局内存那儿,读取与之对应的块的数据,把这些读取的数据,放置到达这个局部内存之中。
声明一个局部变量A_local,它的下标使用局部变量local_y和local_x,将其重新赋值为A下标是a加上A数组宽度再乘以局部变量local_y加上局部变量local_x所对应的值。
对于B_local数组中位于local_x和local_y位置处的值,将其设定为B数组中对应位置的值。该对应位置是通过b加上B_width与local_y的乘积再加上local_x计算得出。同时要等待整个模块被加载完成。
巴瑞尔(时钟局部内存栅栏);,计算部分,把计算单元并行展开,进而形成乘法加法树。
#pragma unroll
对于,整型变量k,赋值为0,当k小于BLOCK_SIZE时,执行循环,每次循环k自增1。
先将running_sum加上,A_local数组中local_y位置的元素乘以B_local数组中local_x位置的同索引元素,乘以k后得到的值 ,最后的结果赋值给running_sum。
等待那块被全然消耗掉以来再去装载下一块之前 ,等候被该拦挡物全然消耗净尽从而在加载下一个封闭区域之前。
barrier(CLK_LOCAL_MEM_FENCE);
}//将结果存储在矩阵CC中,CC[调用获取全局处理器1的标识号(1)乘上调用获取全局大小的函数(0)加上调用获取全局处理器0的标识号(0)]等于连续和之和。
采用 CPU 模拟仿真 FPGA
在对其开展仿真操作时,不用programer操心具体的时序究竟是怎样行进的,仅仅只需去验证逻辑功能就行了,Altera OpenCL SDK能够提供CPU仿真Device设备的功能,是按照如下的方式来予以进行的:
将,用于生成,一个,针对特定加速器板,进行调试的,.aocx文件,执行命令,$ aoc -march=emulator,设备路径为,device/matrix_mult.cl,输出结果到,bin/matrix_mult.aocx,同时,使用,–fp-relaxed,–fpc,以及其它参数,–no-interleaving default,指定目标板为,《your-board》,之后,生成,主机可执行文件,执行命令,$ make,最后,为了,运行,该应用程序,执行命令,$ env CL_CONTEXT_EMULATOR_DEVICE_ALTERA=8!
在上述脚本里头,借助 -march=emulator这个设置去创建一个能够用于CPU debug的、具备设备可执行属性的文件,-g添加调试flag,—board用来创建适配该设备的debugging文件,CL_CONTEXT_EMULATOR_DEVICE_ALTERA是用于CPU仿真的设备数量。
当执行上述脚本后,输出如下:
运行环境把CL_CONTEXT_EMULATOR_DEVICE_ALTERA设置为8后去执行,执行的是放在/bin/里的名为host 的程序,并赋予它如下规定的选项等等,即 -ah的值设定为512,-aw的值设定为512,同时使得 -bw的值也设定为512 ,然后呈现出这样的矩阵尺寸情况: 的内容。
A: 512 x 512
B: 512 x 512
C,512乘以512,初始化OpenCL。
平台:阿尔特拉开放计算语言软件开发工具包。
Using 8 device(s)
。..
EmulatorDevice : Emulated Device
Using AOCX: matrix_mult.aocx
Generating input matrices
。..
Time: 5596.620 ms
Kernel时间,(设备0):5500.896毫秒。
。..
核心时间(设备7),为5137.931毫秒,可以这样表述,设备7对应的,核心时间是5137.931毫秒。
Throughput: 0.05 GFLOPS
Computing reference output
Verifying
Verification: PASS
在进行仿真期间,将Device设置予以调整,令其等于8,而后开展模拟操作,针对8个设备所产出的运行情况施加刻画,此运行所对应的是规模为(512, 512) * (512, 512)的矩阵塑造过程,最终经检验核实无误。与此同时呢,后续便可把其予以实打实的编译处理,并在FPGA设备之上达成运行成效咯。
FPGA 设备上运行矩阵乘
在这个特定的时候,实际上要把代码下载到FPGA上去开展执行操作了,就在这个当口,仅仅需要去做一件事情,这件事究竟是什么呢,那便是运用由OpenCL SDK所提供的编译器,把*.cl代码适配到FPGA上,执行的编译命令如下:
对“aoc”,将“device/matrix_mult.cl”置于其中当作参数,再将其输出导向“bin/matrix_mult.aocx”这种生成物,此过程中采用“–fp-relaxed”“–fpc”“–no-interleaving default”等一系列选项,且关联“–board”与《your-board》这个特定标识,最终形成指令执行状态。
这个进程相对迟缓,通常而言需要几小时到十多个小时不等,这是依据 FPGA 上资源规模来确定的。目前这部分时段过长暂时没办法解决 ,因这里的编译 ,实际上是在形成一个能够正常运作的电路 ,软件会开展布局布线等工作。
处于一种等待的状态,一直等到编译这件事情完成之后,把生成出来的那个 matrix_mult.aocx 文件,拿去烧写到 FPGA 上边,到这一步就可以啦。
烧写的命令如下:
运行一个针对名为《your – board》的程序的操作,该操作涉及到一个叫 matrix_mult.aocx 的文件,通过名为 aocl 的工具来进行。
这时候,大功告成,可以运行 host 端程序了:
这似乎并不是一个完整的、可理解的句子内容呀,请你检查并补充完整准确的句子以便我能按照要求进行改写。
A: 512 x 512
B: 512 x 512
C: 512 x 512Initializing OpenCL
Platform: Altera SDK for OpenCL
Using 1 device(s)
《你的板子》: 英特尔下属可编程逻辑器件公司阿尔特拉的开放式计算语言快速路径互联现场可编程门阵列。
Using AOCX: matrix_mult.aocx
Generating input matrices
Time: 2.253 ms
内核时间(设备0情况),为2.191毫秒。
Throughput: 119.13 GFLOPS
Computing reference output
Verifying
Verification: PASS
能够看到,矩阵乘法于 FPGA 之上能够正常地运行,其吞吐大致处于 119GFlops 左右。
小结
上述开发流程中,OpenCL将FPGAer的开发周期大幅解放,而且对于软件开发者而言,上手也较为轻易。这存在他的优势,然而当前开发进程里,仍有一些问题,像:编译器优化不充分,与用RTL编写的在性能方面存在差距;编译至Device端的所需时间太久。不过伴随行业的发展,这些必然会逐渐改进。
未经允许不得转载:openwrt技术分享 » FPGA开发太硬核?OpenCL让C++程序员轻松上手

